In the late 1970’s, people at Bell Laboratories designed the S programming language in order to facilitate interactive exploratory data analysis (Chambers 2016). Instead of writing, compiling, scheduling, and interpreting the output of individual Fortran programs, the goal of S was to conduct all the necessary steps of the analysis on the fly. S achieved this not by replacing the extensive collection of Fortran subroutines, but by providing a special interface language (Becker and Chambers 1985) through which S could communicate with compiled code.
Fast forward more than four decades and an increase by more than three orders of magnitude in storage and processing capability of computers around us. The dominant implementation of S is now R. It is now feasible to implement algorithms solely in R, recouping the potential performance losses by reducing the programmer effort spent debugging and maintaining the code (Nash and Bhattacharjee 2024). Still, the capability of R to be extended by special-purpose compiled code is as important as ever. As of 2024-11-29, 22% of CRAN packages use compiled code. Since the implementation language of R is C, not Fortran, the application programming interface (API) for R is mainly defined in terms of C.
What’s in an API?
Writing R Extensions (“WRE”) is the definitive guide for R package development. Together with the CRAN policy it forms the “rules as written” that the maintainers of CRAN packages must follow. A recent version of R exports 1202 symbols, including 1049 functions (“entry points”, not counting C preprocessor macros) and 153 variables. Not all of them are intended to be used by packages. Even back in R-3.3.0, the oldest version currently supported by data.table, WRE chapter 6, “The R API” classified R’s entry points into four categories:
- API Entry points which are documented in this manual and declared in an installed header file. These can be used in distributed packages and will only be changed after deprecation.
- public Entry points declared in an installed header file that are exported on all R platforms but are not documented and subject to change without notice.
- private Entry points that are used when building R and exported on all R platforms but are not declared in the installed header files. Do not use these in distributed code.
- hidden Entry points that are where possible (Windows and some modern Unix-alike compilers/loaders when using R as a shared library) not exported.
Although nobody objected to the use of the API entry points, and there was little point in trying to use the hidden entry points in a package that would fail to link almost everywhere, the public and the private entry points ended up being a point of contention. Those deemed too internal to use but not feasible to make hidden were (and still are) listed in the character vector tools:::nonAPI: R CMD check looks at the functions imported by the package and signals a NOTE if it finds any listed there.
The remaining public functions, neither documented as API nor explicitly forbidden by R CMD check, sat there, alluring the package developers with their offers. For example, the serialization interface is only documented in WRE since R-4.5, but it has been powering part of the digest CRAN package since 2019 (and other packages before it) without any drastic changes. Some of the inclusions in tools:::nonAPI could have been historical mistakes: while WRE has been saying back in version 3.3.0 that wilcox_free should be called after a call to the (API) functions dwilcox, pwilcox or qwilcox, the function was only declared in the public headers and removed from tools:::nonAPI in R-4.2.0. Still, between R-3.3.3 and R-4.4.2, the #define USE_RINTERNALS escape hatch finally closed, tools:::nonAPI grew from 259 to 272 entries, and the package maintainers had to adapt or face archival of their packages.
A recent question on R-devel (whether the ALTREP interface should be considered “API” for the purpose of CRAN package development) sparked a series of events and an extensive discussion containing the highest count of occurrences of the word “API” per month ever seen on R-devel (234), topping October 2002 (package versioning and API breakage, 150), October 2005 (API for graphical interfaces and console output, 124), and May 2019 (discussions of the ALTREP interface and multi-threading, 121). As a result, Luke Tierney started work on programmatically describing the functions and other symbols exported by R (including variables and preprocessor and enumeration constants), giving a stronger definition to the interface. His changes add the currently unexported function tools:::funAPI() that lists entry points and two more of their categories:
- experimental Entry points declared in an installed header file that are part of an experimental API, such as
R_ext/Altrep.h. These are subject to change, so package authors wishing to use these should be prepared to adapt.- embedding Entry points intended primarily for embedding and creating new front-ends. It is not clear that this needs to be a separate category but it may be useful to keep it separate for now.
Additionally, WRE now spells out that entry points not explicitly documented or at least listed in the output of tools:::funAPI (or something that will replace it) are now off-limits, even if not currently present in tools:::nonAPI (emphasis added):
- public Entry points declared in an installed header file that are exported on all R platforms but are not documented and subject to change without notice. Do not use these in distributed code. Their declarations will eventually be moved out of installed header files.
Correspondingly, the number of tools:::nonAPI entry points in the current development version of R rose to 322, prompting the blog post you are currently reading.
Non-API entry points marked by R CMD check
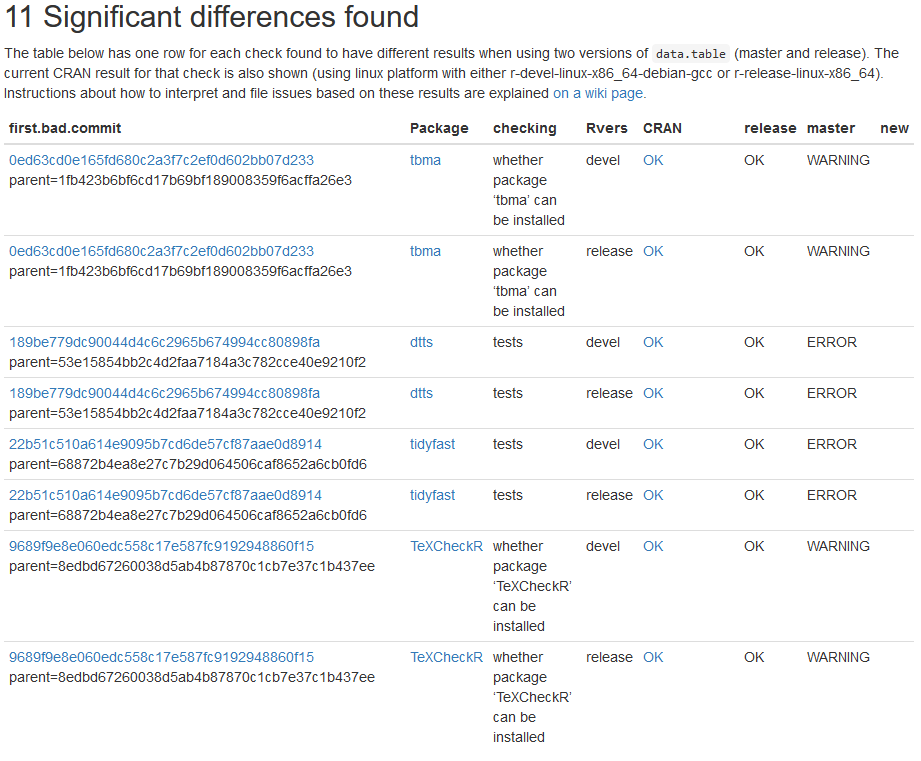
The first version of the data.table package in the CRAN archive dates back to April 2006 (which corresponds to R version 2.3.0). It has been evolving together with R and its API and thus has accumulated a number of uses of R internals that are now flagged by R CMD check as non-API:
Package: data.table 1.16.2 Flavor: r-devel-linux-x86_64-debian-clang Check: compiled code, Result: NOTE File ‘data.table/libs/data_table.so’: Found non-API calls to R: ‘LEVELS’, ‘SETLENGTH’, ‘SET_GROWABLE_BIT’, ‘SET_TRUELENGTH’, ‘STRING_PTR’, ‘TRUELENGTH’ Compiled code should not call non-API entry points in R. See ‘Writing portable packages’ in the ‘Writing R Extensions’ manual, and section ‘Moving into C API compliance’ for issues with the use of non-API entry points.
– R CMD check --as-cran on a released version of data.table
Operating on the S4 bit: IS_S4_OBJECT, SET_S4_OBJECT, UNSET_S4_OBJECT
In R’s “S4” OOP system, objects can have a primitive base type (e.g. setClass("PrimitiveBaseType", contains = "numeric") or no base type at all (e.g. setClass("NoBaseType")). In the former case, their SEXPTYPE code is that of their base class (e.g. REALSXP). In the latter case, their type code is OBJSXP (previously S4SXP, which is now an alias for OBJSXP). To make both cases work consistently, R uses a special “S4” bit in the header of the object.
The data.table class is registered with the S4 OOP system, making it possible to create S4 classes containing data.tables as members (setClass(slots = c(mytable = 'data.table'))) or even inheriting from data.table (and, in turn, from data.frame: setClass(contains = 'data.table')). Additionally, data.tables may contain columns that are themselves S4 objects, and both of these cases require care from the C code.
The undocumented functions IS_S4_OBJECT, SET_S4_OBJECT, UNSET_S4_OBJECT exist as bare interfaces to the internal macros of the same names and directly access the flag inside their argument. Writing R Extensions documents Rf_isS4 and Rf_asS4 as their replacements.
The Rf_isS4 function is a wrapper for IS_S4_OBJECT that follows the usual naming convention for remapped functions, has been part of the API for a long time, and could implement additional checks if they are needed by R. The Rf_asS4 function (experimental API) is more involved, trying to “deconstruct” S4 objects into S3 objects if possible and requested to. If the reference count of its argument is above 1, it will operate upon and return its shallow duplicate.
data.table used to directly operate on the S4 bit in two places, the shallow function in src/assign.c and the keepattr function in src/dogroups.c. In both cases, this was required after directly modifying attribute list using the undocumented function SET_ATTRIB. For shallow, the solution was to replace the manual operation of attributes with SHALLOW_DUPLICATE_ATTRIB (API, available since 3.3.0), which itself takes care of invariants like the object bit and the S4 bit.
The keepattr function is only used in growVector to transplant all attributes from a vector to its enlarged copy without duplicating them, for which no API exists. The solution is to use Rf_asS4 to control the S4 object bit, knowing that the new vector is freshly allocated and thus cannot be shared yet.
Converting between calls and pairlists: SET_TYPEOF
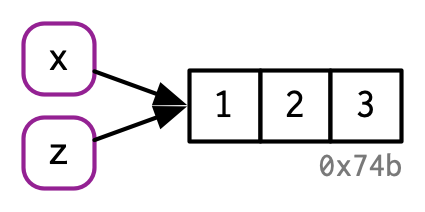
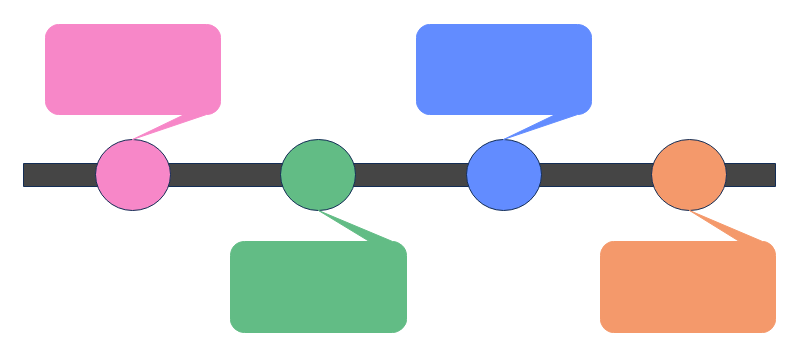
In R, function calls are internally represented as Lisp-style pairlists where the first pair is of special type LANGSXP instead of LISTSXP. For example, the following diagram illustrates the data structure of the call print(x = 42L):

Here, every list item is a separate R object, a “cons cell”; each cell contains the value in its CAR field and a reference to the rest of the list in its CDR field. Argument names, if provided, are stored in the third field, TAG. The list is terminated by R_NilValue, which is of type NILSXP. These structures must be constructed every time C code wants to evaluate a function call (e.g.).
Previously, R API contained a function to allocate LISTSXP pairlists of arbitrary length, allocList(), but not function calls, so it became a somewhat common idiom to first allocate the list and then use SET_TYPEOF to change the type of the head pair to LANGSXP. This did not previously lead to problems, since the two types have the same internal memory layout.
The danger of SET_TYPEOF lies in the possibility to set the type of an R value to one with an incompatible memory layout. (For example, vector types REALSXP and INTSXP are built very differently from cons cells LISTSXP and LANGSXP.) Starting with R-4.4.1, R contains the allocLang function in addition to the allocList function that directly allocates a function call object with a head pair of type LANGSXP. In order to stay compatible with previous R versions, packages may allocate the LISTSXP tail first and then use lcons() to construct the LANGSXP head pair of the call.
Problem (the only instance in data.table):
SEXP s = PROTECT(allocList(2));
SET_TYPEOF(s, LANGSXP);
// ^^^^^^^^^^ unsafe operation, could be used to corrupt objects
SETCAR(s, install("format.POSIXct"));
SETCAR(CDR(s), column);Solutions:
// for fixed-size calls with contents known ahead of time
SEXP s = lang2(install("format.POSIXct"), column);or:
// partially pre-populate
SEXP s = lang2(install("format.POSIXct"), R_NilValue);
// later, when 'column' is known:
SETCAR(CDR(s), column);or:
// allocate a call with 'n' elements
SEXP call = lcons(R_NilValue, allocList(n - 1));or:
// in R >= 4.4.1 only:
SEXP call = allocLang(n);Unfortunately, the LCONS macro didn’t work with #define R_NO_REMAP prior to R-4.4, because it expanded to lcons() instead of Rf_lcons().
Status in data.table: fixed in #6313.
Strings as C arrays of CHARSXP values: STRING_PTR
From the point of view of R code, strings are very simple things, much like numbers: they live in atomic vectors and can be directly compared with other objects. It is only natural to desire to work with them as easily from C code as it’s possible with other atomic types, where functions REAL(), INTEGER(), or COMPLEX() can be used to access the buffer containing the numbers.
The underlying reality of strings is more complicated: since they internally manage memory buffers containing text in a given encoding, they must be subject to garbage collection. Like other managed objects in R, they are represented as SEXP values of special type CHARSXP. R’s garbage collector is generational and requires the use of write barrier (1, 2) any time a SEXP value (such as an STRSXP vector) references another SEXP value (such as a CHARSXP string). In a generational garbage collector, “younger” generations are marked and sweeped more frequently than “older” ones, because in a typical R session, most objects are temporary (Jones, Hosking, and Moss 2012, chap. 9). If package C code manually writes a reference to a “young” CHARSXP object into an “old” STRSXP vector without taking generations into account, a following collection of the “young” pool of objects will miss the CHARSXP being referenced by the “old” STRSXP and remove the CHARSXP as “garbage”. This makes the SEXP * pointers returned by STRING_PTR unsafe and requires the use of STRING_PTR_RO function, which returns a read-only const SEXP *.
Thankfully, data.table has already been using read-only const SEXP * pointers when working with STRSXP vectors, so the required changes to the code were not too substantial, limited to the name of the function:
Example of the problem:
const SEXP *sourceD = STRING_PTR(source);
// ^^^^^^^^^^
// returns a writeable SEXP * pointer, therefore unsafeSolution:
#if R_VERSION < R_Version(3, 5, 0)
// STRING_PTR_RO only appeared in R-3.5
#define STRING_PTR_RO(x) (STRING_PTR(x))
#endif
// later:
const SEXP *sourceD = STRING_PTR_RO(source);
// ^^^^^^^^^^^^^
// returns a const SEXP * pointer, which prevents accidental writesReading the reference counts: NAMED
In plain R, all value types – numbers, strings, lists – have pass-by-value semantics. Without dark and disturbing things in play, such as non-standard evaluation or active bindings, R code can give a plain value (x <- 1:10) to a function (f(x)) or store it in a variable (y <- x), have the function modify its argument (f <- \(x) { x[1] <- 0 }) or change the duplicate variable (y[2] <- 3), and still have the original value intact (stopifnot(identical(x, 1:10))). Only the inherently mutable types, such as environments, external pointers and weak references, will stay shared between all assignments and function arguments; the value types behave as if R copies them every time.
And yet actually making these copies is wasteful when the code only reads the variable and does not alter it. (In fact, one of the original motivations of data.table was to reduce certain wasteful copying of data that happens during normal R computations.) Until version 4.0.0, NAMED was R’s mechanism to save memory and CPU time instead of creating and storing these copies. A temporary object such as the value of 1:10 was not bound to a symbol and thus could be modified right away. Assigning it to a variable, as in x <- 1:10, gave it a NAMED(x) count of 1, for which R had an internal optimisation in replacement function calls like foo(x) <- 3. Assigning the same value to yet another symbol (by copying y <- x or calling a function foo(x)) increased the NAMED() count to 2 or more, for which there was no optimisation: in order to modify one of the symbols, R was required to duplicate x first. NAMED() was not necessarily decreased after the bindings disappeared, and decreasing it after having reached NAMEDMAX was impossible. During the lifetime of R-3.x, NAMEDMAX was increased from 2 to 3 and later to 7.
Between R-3.1.0 and R-4.0.0, R migrated from NAMED to reference counting. Reference counts are easier to properly decrement than NAMED, thus preventing unneeded copies of objects that became unreferenced. R-3.5.0 documented the symbols MAYBE_REFERENCED(.) / NO_REFERENCES(.) for use instead of checking NAMED(.) == 0, MAYBE_SHARED(.) / NOT_SHARED(.) instead of checking NAMED(.) > 1, and MARK_NOT_MUTABLE(.) instead of setting NAMED(.) to NAMEDMAX, which later became part of the API instead of the NAMED(.) and REFCNT(.) functions. The hard rules are that a value is safe to modify in place if it has NO_REFERENCES() (reference count of 0), definitely unsafe to modify in place (requiring a call to duplicate or shallow_duplicate) if it is MAYBE_SHARED() (reference count above 1), and almost certainly unsafe to modify in place if it is MAYBE_REFERENCED() (reference count of 1).
data.table’s only uses of NAMED() were in the verbose output during assignment:
if (verbose) {
Rprintf(_("RHS for item %d has been duplicated because NAMED==%d MAYBE_SHARED==%d, but then is being plonked. length(values)==%d; length(cols)==%d)\n"),
i+1, NAMED(thisvalue), MAYBE_SHARED(thisvalue), length(values), length(cols));
// ^^^^^ non-API function
}Since the correctness of the modification operation hinges on the reference count being 0 (and it may be important whether it’s exactly 1 or above 1), the same amount of useful information can be conveyed by printing MAYBE_REFERENCED() and MAYBE_SHARED() instead of NAMED():
if (verbose) {
Rprintf(_("RHS for item %d has been duplicated because MAYBE_REFERENCED==%d MAYBE_SHARED==%d, but then is being plonked. length(values)==%d; length(cols)==%d)\n"),
i+1, MAYBE_REFERENCED(thisvalue), MAYBE_SHARED(thisvalue), length(values), length(cols));
// ^^^^^^^^^^^^^^^^ API function
}Status in data.table: fixed in #6420.
Encoding bits: LEVELS
LEVELS is the name of the internal R macro and an exported non-API function accessing a 16-bit field called gp (general-purpose) that is present in the header of every SEXP value. Not every access to this field is done using the LEVELS() macro; there are bits of R code that access (sexp)->sxpinfo.gp directly. R uses this field for many purposes:
- matching given arguments against the formals of a function (1, 2, 3)
- remembering the previous type of a garbage-collected value
- finalizing the reference-semantics objects before garbage-collecting them
- marking condition handlers as “calling” (executing on top of where the condition was signalled in the call stack), as opposed to “non-calling” (executing at the site of the
tryCatchcall) - marking objects in complex assignment calls
- storing the S4 object bit
- marking functions as (un)suitable for bytecode compilation
- marking vectors as growable
- marking provided (“actual”) function arguments as missing
- marking the
..1,..2, etc symbols as corresponding to the given element of the...argument - marking environments as locked, or for caching the global variable lookup, or for looking up values in the base environment or the special functions (1, 2, 3, 4)
- marking symbols naming environment contents for hash lookup
- marking bindings inside environments as active
- marking promise objects as already evaluated
- marking
CHARSXPvalues as present in the global cache or being in a certain encoding
Although the value of gp is directly stored in R’s serialized data stream, neither of these are part of the API. Out of all possible uses for this flag, data.table is only interested in string encodings. From the viewpoints of plain R and the C API, an individual string (CHARSXP value) can be marked with the following encodings:
| R-level encoding name | C-level encoding constant | Meaning |
|---|---|---|
"latin1" |
CE_LATIN1 |
ISO/IEC 8859-1 or CP1252 |
"UTF-8" |
CE_UTF8 |
ISO/IEC 10646 |
"unknown" |
CE_NATIVE |
Encoding of the current locale |
"bytes" |
CE_BYTES |
Not necessarily text; translateChar will fail |
Internally, R also marks strings as encoded in ASCII: since all three encodings are ASCII-compatible, an ASCII string will never need to be translated into a different encoding. Note that there is a subtle difference between a string marked in a certain encoding and actually being in a certain encoding: in an R session running with a UTF-8 locale (which includes most modern Unix-alikes and Windows ≥ 10, November 2019 update) a string marked as CE_NATIVE will also be in UTF-8. (Similarly, with an increasingly rare Latin-1 locale, a CE_NATIVE string will be in Latin-1.)
The data.table code is interested in knowing whether a string is marked as UTF-8, Latin-1, or ASCII. This is used to convert strings to UTF-8 when needed (also: output to native encoding or UTF-8 in fwrite, automatic conversion in forder). The getCharCE API function appeared in R-2.7.0 together with the encoding support, so switching the IS_UTF8 and IS_LATIN macros from LEVELS to API calls was relatively straightforward.
R-4.5.0 is expected to introduce the charIsASCII “experimental” API function that returns the value of the ASCII marker for a CHARSXP value, which will replace the use of LEVELS in the IS_ASCII macro. Curiously, while it looks like the code could benefit from switching from the getCharCE() tests (which only look at the value of the flags and so may needlessly translate strings from CE_NATIVE) to the new experimental charIs(UTF8|Latin1) functions that will also return TRUE for a matching native encoding, actually making the change breaks a number of unit tests.
Status in data.table: partially fixed in #6420, waiting for R-4.5.0 to be released with the new API in #6422.
SETLENGTH, SET_GROWABLE_BIT, (SET_)TRUELENGTH
Growable vectors
Since data.frames and data.tables are lists, and lists in R are value types with pass-by-value semantics, adding or removing a column to one normally involves allocating a new list referencing the rest of the columns (performing a “shallow duplicate”). By contrast, the over-allocated lists can be resized in place by gradually increasing their LENGTH (remembering their original length in the TRUELENGTH field), obviating the need for shallow duplicates at the cost of making data.tables shared, by-reference values. The change has been introduced in v1.7.3, November 2011, together with the := operator for changing the columns by reference (which has since become the defining feature of data.table).
R’s own use of TRUELENGTH is varied. The field itself appeared in R-0.63 together with the VECSXP lists (to replace the Lisp-style linked pairlists). R uses this field in CHARSXP strings to store the hash values belonging to symbols. R’s many VECSXP-based hash tables use it to count the primary slots in use: hashes are used for reference tracking during (un)serialization (1, 2) and looking up environment contents (1, 2). R-3.3 (May 2016) saw the inclusion of radix sort from data.table itself, which uses TRUELENGTH to sort strings. R-3.4 (April 2017) introduced over-allocation when growing vectors due to assignment outside their bounds. The growable bit was added to prevent the mismanagement of the allocated memory counter: without the bit set on the over-allocated vectors, the garbage collector only counted LENGTH(x) instead of TRUELENGTH(x) units as released when garbage-collecting the vector, inflating the counter over time. ALTREP objects introduced in R-3.5 (April 2018) don’t have a TRUELENGTH: it cannot be set and is returned as 0. In very old versions of R, TRUELENGTH wasn’t initialised, but it is nowadays set to 0, which data.table depends upon.
Nowadays, data.table uses vectors whose length is different from their allocated size in many places:
src/dogroups.c- reuses the same memory for the
data.tablesubset object.SDand for the virtual row number column.Iby shortening the vectors to the size of the current group - later restores their natural length
- extends the
data.tablefor new columns as needed
- reuses the same memory for the
src/freadR.c- works with an over-estimated line count and so can truncate the columns after the value is known precisely
- the columns are prepared to be truncated
- may also drop columns by reference
- works with an over-estimated line count and so can truncate the columns after the value is known precisely
src/subset.c- the
subsetDTfunction prepares an over-allocateddata.tabletogether with its names.
- the
src/assign.c- the
shallowfunction prepares an over-allocateddata.tablereferencing the columns of an existingdata.table assigncreates or removes columns by referencefinalizercauses anINTSXPvector with the fake length to be (eventually) garbage-collected to fix up a discrepancy in R’s vector size accounting caused by the existence of the over-allocateddata.table
- the
SETLENGTH presents many opportunities to create inconsistencies within R:
- When copying shortened objects without the
GROWABLE_BITset, R allocates and copies onlyXLENGTHelements and duplicates the value ofTRUELENGTH.- For this and other reasons,
data.tables have a special.internal.selfrefattribute attached containing anEXTPTRback to itself. A copy of a table can be detected because it will have a different address.- The
_selfrefokfunction tries to restore the correctTRUELENGTHif it detects a copy.
- The
- Setting the
GROWABLE_BITon thedata.tablewould make R keep the defaultTRUELENGTH(0) instead of copying it.
- For this and other reasons,
- When deallocating shortened objects without the
GROWABLE_BITset, R accounts only for theXLENGTHelements being released, over-counting the total amount of allocated memory.data.tablecompensates for this using thefinalizeron the.internal.selfrepattribute.- Setting the
GROWABLE_BITon thedata.tablewould make R account forTRUELENGTHelements instead ofXLENGTHelements.
Unfortunately, GROWABLE_BIT is not part of the API and was only introduced in R-3.4, so it does not present a full solution to the problems. Moreover,
Setting
LENGTHlarger than the allocated length may cause R to access undefined or even unmapped memory.For vectors containing other
SEXPvalues (of typeVECSXP,EXPRSXP,STRSXP): when reducing theLENGTH, having a non-persistent value (something unlike the persistent valuesR_NilValueorR_BlankStringorR_NaStringprovided by R itself) in the newly inaccessible cells will also make them unreachable from the viewpoint of the garbage collector, potentially prompting it to reuse or unmap the pointed-to memory. Increasing theLENGTHagain with invalid pointers in the newly accessible slots will make an invalid vector that cannot be safely altered or discarded:#include <R.h> #include <Rinternals.h> void foo(void) { { SEXP list = PROTECT(allocVector(VECSXP, 100)), elt; SET_VECTOR_ELT(list, 99, elt = allocVector(REALSXP, 1000)); double * p = REAL(elt); // initialise the vector for (R_xlen_t i = 0; i < xlength(elt); ++i) p[i] = i; SETLENGTH(list, 1); // elt is unreachable R_gc(); // elt is collected SETLENGTH(list, 100); // invalid elt is reachable again R_gc(); // invalid elt is accessed UNPROTECT(1); } R_gc(); // crash here if not above }
Starting with R-4.3, R packages can implement their own VECSXP-like objects using the ALTREP framework; STRSXP objects have been supported since R-3.5. An ALTREP object is defined by its class (a collection of methods) and two arbitrary R values, data1 and data2. (Attributes are not a part of the ALTREP representation and exist the same way as on normal R objects.) A simple implementation of a shortened, expandable vector could hold a full-length vector in the data1 slot and its pretend-length as a one-element REALSXP value in the data2 slot. (Currently, R_xlen_t values are limited by the largest integer precisely representable in an IEEE double value, which is \(2^{52}\).) The over-allocated class will need to implement the following methods:
- Common ALTREP methods:
Length(), returning the pretend-length of the vector. Required.Duplicate(deep). If not implemented, R will create a copy as an ordinary object using the length and the data pointer provided by the class.- There is also
DuplicateEX(deep), which is responsible for copying the value and the attributes, but it may be hard to implement within the API bounds (ATTRIBis not API), and R provides a default implementation that callsDuplicateabove. - Shared mutable vectors can cause problems, so a decision to let the
Duplicate()return value share the original vector will require a lot of thought and testing.
- There is also
Serialized_state(),Unserialize(state). If not implemented, R will serialize the value as an ordinary object, which is what currently happens fordata.tables. Once an R package implements an ALTREP class with aSerialized_statemethod, the format is set in stone; any changes will have to introduce a new class.- Similarly, there is
UnserializeEX(state, attr, objf, levs)responsible for settingLEVELS, the object bit, and the attributes; the default implementation should suffice.
- Similarly, there is
Inspect(pre, deep, pvec, inspect_subtree). MayRprintfsome information from the ALTREP fields before returningFALSEto let R continueinspecting the object.
- Common
altvecmethods required for most code to work with the class:Dataptr(writable), returning the pointer to the start of the array backing the underlying vector. ForVECSXPorSTRSXPvectors,writableshould always beFALSE, soDATAPTR_ROcan be used.Dataptr_or_null(). May delegate toDataptr(FALSE)above.Extract_subset(indx, call). Must allocate and returnx[indx]for 1-based numericindxthat may be outside the bounds ofx.
- Class-specific methods:
altstringmethods:Elt(i). Must returnx[[i]]for 0-basedior signal an error. Required.Set_elt(i, v). Must performx[[i]] <- vfor 0-basedior signal an error. Required.Is_sorted(). If not implemented, will always returnUNKNOWN_SORTEDNESS.No_NA(). If not implemented, will always return 0 (unknown whether contains missing values).
altlistmethods:Elt(i)andSet_elt(i, v)like above.
- The rest of the atomic vector types (integer, logical, numeric, complex, raw) will each need a subset of the following methods:
Elt(i),Is_sorted(),No_NA(), as above.Get_region(i, n, buf)to populate the bufferbuf[n]of the corresponding C type with elements at the given 0-based indicesi. The indices are not guaranteed to be within bounds; the number of actually copied elements must be returned. If not implemented, R will use theElt(i)method, which is slower.Sum(narm),Min(narm),Max(narm)to compute a summary of the vector, optionally ignoring the missing values. If not implemented, R will useGet_regionto compute the summaries.
Additionally, data.table will need a function to create new ALTREP tables and to resize the vector in place. The resize function will need to check whether the given value R_altrep_inherits from the over-allocated class and then modify the ALTREP data slots as needed. The function may even reallocate the payload to enlarge the vector in place past the original allocation limit without requiring a setDT call from the user. Since a reallocation will invalidate the data pointer, it must be only used from inside data.table, not from the ALTREP methods.
The original implementation that uses SETLENGTH can be kept behind #if R_VERSION < R_Version(4, 3, 0) for backwards compatibility.
Replacing TRUELENGTH-based growable vectors with ALTREP-based ones will conform to the API, allow growing the vector in place, and avoid the various inconsistencies that happen when R duplicates or deallocates these vectors, but also has the following downsides:
- Every place in
data.tablethat uses growable vectors will have to be refactored to use the new abstraction layer (SETLENGTHin R < 4.3, ALTREP in R ≥ 4.3).- Both implementations will have to be maintained as long as
data.tablesupports R < 4.3. - The current implementation in
data.tablere-creates ALTREP objects as ordinary ones precisely because it’s impossible toSET_TRUELENGTHon ALTREP objects. This will also need to be refactored.
- Both implementations will have to be maintained as long as
- The data pointer access is slower for ALTREP vectors than for ordinary vectors: having checked the ALTREP bit in the header, R will have to access the method table and call the method instead of adding a fixed offset to the original
SEXPpointer. This shouldn’t be noticeable unlessdata.tableputs data pointer access inside a “hot” loop. - For numeric ALTREP classes, ALTREP-aware operations that use
*_GET_REGIONinstead of the data pointer will become slower unless the class implements aGet_regionmethod.
Status in data.table: not fixed yet.
Fast string matching
data.table’s use of TRUELENGTH is not limited to growable buffers. A common idiom is to set the TRUELENGTHs of CHARSXP values from a vector to their negative 1-based indices in that vector, then look up other CHARSXPs in the original vector using -TRUELENGTH(s). This technique relies on R’s CHARSXP cache: for the given string contents and encoding, only one copy of a string created by mkCharLenCE (and related functions) will exist in the memory. As a result, if a string does exist in the original vector, it will be the same CHARSXP object whose TRUELENGTH had been set to its negative index. R does not currently set negative TRUELENGTHs by itself, so any positive TRUELENGTHs can be safely discarded as non-matches.
In the best case scenario, this lookup is very fast: for a table of size \(n\) and \(k\) strings to look up in it, it takes \(\mathrm{O}(1)\) memory (the TRUELENGTH is already there, unused) and \(\mathrm{O}(n)\) time for overhead plus \(\mathrm{O}(k)\) time for the actual lookups.
Care must be taken for the technique to work properly:
The strings must be converted to UTF-8. Two copies of the same text in different encodings will be stored in different objects at different addresses, preventing the technique from working:
packageVersion('data.table') # [1] ‘1.16.99’ x <- data.table(factor(rep(enc2utf8('ø'), 3))) # memrecycle() forgot to account for encodings x[1,V1 := iconv('ø', to='latin1')] as.numeric(x$V1) # [1] 2 1 1 levels(x$V1) # duplicated levels! # [1] "ø" "ø" identical(levels(x$V1)[[1]], levels(x$V1)[[2]]) # [1] TRUE levels(x$V1) <- levels(x$V1) levels(x$V1) # R restores unique levels # [1] "ø"Any non-zero
TRUELENGTHvalues resulting from R-internal usage must be saved beforehand and restored afterwards.The
TRUELENGTHs are used to look up variables in hashed environments, so R code should not run while the values are disturbed.
The encoding conversions take \(\mathrm{O}(n+k)\) time and space; the TRUELENGTH bookkeeping takes \(\mathrm{O}(n)\) space and time (thanks to the exponential realloc trick).
The fast string lookup is used in the following places:
src/assign.c: factor level merging inmemrecycle,savetlhelpersrc/rbindlist.c: matching column names, matching factor levelssrc/forder.c: (different purpose, same technique) storing the group numbers, looking them up, restoring the original valuessrc/chmatch.c: saving the originalTRUELENGTHs, remembering the positions ofCHARSXPs in the table, cleaning up on error, looking up strings in the table, cleaning up before exitsrc/fmelt.c: combining factor levels by merging theirCHARSXPs in a common array with indices inTRUELENGTH
Since there doesn’t seem to be any intent to allow using R API to place arbitrary integer values inside unused SEXP fields, data.table will have to look up the CHARSXP values using the externally available information. Performing \(\mathrm{O}(nk)\) direct pointer comparisons would scale poorly, so for an \(\mathrm{O}(1)\) individual lookup data.table could build a hash table of SEXP pointers. While pointer hashing isn’t strictly guaranteed by the C standard to work, it has been used in R itself. A hash table for \(n\) CHARSXP pointers would need \(\mathrm{O}(n)\) memory, \(\mathrm{O}(n)\) time to initialise, and average \(\mathrm{O}(k)\) time for \(k\) lookups (Cormen et al. 2009, chap. 11).
Taking the savetl bookkeeping into account, the average asymptotic performance of TRUELENGTH and hashing for string lookup is the same in both time and space, but the constants are most likely lower for TRUELENGTH. Transitioning to a hash will probably involve a performance hit.
A truly lazy implementation could just use std::unordered_map<SEXP, int> (at the cost of requiring C++11, which was supported but far from required in R-3.3, and having to shield R from the C++ exceptions) or the permissively-licensed uthash. Since the upper bound on the size of the table is known ahead of time, a custom-made open-addressing hash table (Cormen et al. 2009, sec. 11.4) could be implemented with a fixed load factor, requiring only one allocation and no linked lists to walk.
Status in data.table: not fixed yet.
Marking columns for copying
The use of TRUELENGTH in data.table to mark objects is not limited to CHARSXP strings. Individual columns are also marked in a similar manner for later copying:
- In
src/dogroups.c, the vectors allocated for the special symbols.BY,.I,.N,.GRPmust not be returned by the grouping operations evaluated withdt[..., ..., by=...], so they are marked with aTRUELENGTHof -1, and the marked columns are later re-created. - In
src/utils.c, columns share memory or are ALTREP must be copied. Memory sharing between columns may lead to confusing results when they are altered by reference, and ALTREP columns cannot haveTRUELENGTHset. The code uses the same trick as withCHARSXPobjects: ifTRUELENGTHis set on an object, accessing it through a different pointer and seeing a non-zero value will prove that the object had been previously visited. The code first prepares zeroTRUELENGTHs, then marks ALTREP, special, and already marked columns for copying, then marks columns not previously marked with their column number, then finally restores theTRUELENGTHs for the columns that won’t be overwritten.- The
SET_TRUELENGTHcall incopySharedColumnswould fail if it ever got an ALTREP column, but the only use ofcopySharedColumnsinreorderguards against those.
- The
The same solution as above can be used here, with the same downsides of having to allocate memory for the hash table and the potential to have worst-case \(\mathrm{O}(kn)\) time for \(k\) lookups fundamental to hash tables.
Status in data.table: not fixed yet.
But there’s more
Using tools:::funAPI together with the lists of symbols exported from R and imported by data.table, we can find a number of non-API entry points which R CMD check doesn’t complain about yet: ATTRIB, findVar, GetOption, isFrame, OBJECT, SET_ATTRIB, SET_OBJECT.
(SET_)ATTRIB, SET_OBJECT
data.table performs some direct operations on the attribute pairlists. Accessing attributes directly requires manually maintaining the object bit.
Use
getAttribfor individual attributes. To test whether there are any attributes useANY_ATTRIB, added in R 4.5.0. UsesetAttribfor individual attributes,DUPLICATE_ATTRIBorSHALLOW_DUPLICATE_ATTRIBfor copying attributes from one object to another. UseCLEAR_ATTRIBfor removing all attributes, added in R 4.5.0.
Testing for presence of attributes
src/nafill.c checks whether the source object has any attributes before trying to copy them using copyMostAttrib.
Problem:
if (!isNull(ATTRIB(VECTOR_ELT(x, i))))
// ^^^^^^ non-API entry pointSolution:
#if R_VERSION < R_Version(4, 5, 0)
#define ANY_ATTRIB(x) (!isNull(ATTRIB(x)))
#endif
if (ANY_ATTRIB(VECTOR_ELT(x, i)))
// ^^^^^^^^^^ introduced in R-4.5Status in data.table: not fixed yet. Will need to wait for R-4.5.0 to be released with the new interface.
Iterating over all attributes
- The code in
src/assign.cneeds to iterate over all the attributes ofattr(dt, 'index')in order to find indices that use the given column. - The code in
src/dogroups.cneeds to iterate over all attributes of a column in case a reference to the value of a special symbol has been stashed there and must be duplicated.
Without ATTRIB, this will only be possible using an R-level call to attributes(). While the indices could be changed to use a different data structure (a named VECSXP list?), necessitating an update step for data.tables loaded from storage, the code in src/dogroups.c cannot avoid having to see all the attributes.
Status in data.table: no idea how to fix yet.
Raw c(NA, n) row names
The code in src/dogroups.c needs to access the raw rownames attribute of a data.table, even if it’s in the compact form as a 2-element integer vector starting with NA. The getAttrib function has a special case for the R_RowNamesSymbol, which returns an ALTREP representation of this attribute.
data.table needs this access in order to temporarily overwrite the rownames attribute for the specially-prepared subset data.table named .SD (which has a different number of rows and therefore needs different rownames). Creating a full-sized rownames attribute instead of its compact form would take more time than desirable.
Status in data.table: no idea how to fix yet.
Direct transplantation of attributes
The code in src/dogroups.c needs to transplant the attributes from one object to another without duplicating them, even shallowly. SHALLOW_DUPLICATE_ATTRIB could work as a replacement, but with worse performance because it would waste time copying attributes from an object that is about to be discarded.
Status in data.table: no idea how to fix yet.
findVar
Used in dogroups to look up the pre-created variables corresponding to the special symbols .SDall, .SD, .N, .GRP, .iSD, .xSD in their environment.
The functions
findVarandfindVarInFramehave been used in a number of packages but are too low level to be part of the API. For most uses the functionsR_getVarandR_getVarExadded in R 4.5.0 will be sufficient. These are analogous to the R functionsgetandget0.
The new function R_getVar is different in that it will never return a PROMSXP (which are an internal implementation detail) or an R_UnboundValue, but the current code doesn’t try to care about either.
Example of the problem:
SEXP SD = PROTECT(findVar(install(".SD"), env));
// ^^^^^^^ non-API functionSolution:
#if R_VERSION < R_Version(4, 5, 0)
#define R_getVar(sym, rho, inherits) \
((inherits) ? findVar((sym), (rho)) : findVarInFrame((rho), (sym)))
#endif
SEXP SD = PROTECT(R_getVar(install(".SD"), env, TRUE));
// ^^^^^^^^ introduced in R-4.5Status in data.table: not fixed yet. Will need to wait for R-4.5.0 to be released with the new interface.
GetOption
Used in src/rbindlist.c to read the datatable.rbindlist.check option, src/freadR.c to read the datatable.old.fread.datetime.character option, src/init.c to read the datatable.verbose option, src/forder.c to get the datatable.use.index and datatable.forder.auto.index options, and src/subset.c to read the datatable.alloccol option.
Use
GetOption1.
The difference is that GetOption1 doesn’t take a second argument rho, which GetOption has been ignoring anyway.
Example of the problem:
SEXP opt = GetOption(install("datatable.use.index"), R_NilValue);
// ^^^^^^^^^ non-API functionSolution:
SEXP opt = GetOption1(install("datatable.use.index"));
// ^^^^^^^^^^ API function introduced in R-2.13Status in data.table: not fixed yet.
Testing for a data.frame: isFrame
Back in 2012, Matt Dowle needed to quickly test an object for being a data.frame, and the undocumented function isFrame seemed like it did the job. Since isFrame was not part of the documented interface, in 2024 Luke Tierney gave the function a better-fitting name, isDataFrame, and made it an experimental entry point, while retaining the original function as a wrapper.
Use of isFrame doesn’t give a NOTE yet, but when R-4.5.0 is released together with the new name for the function, data.table will be able to use it, falling back to isFrame on older versions of R. isDataFrame is documented among other replacement entry point names in Writing R Extensions.
Problem (the only instance in data.table):
if (!isVector(thiscol) || isFrame(thiscol))
// ^^^^^^^ may disappear in a future R versionSolution:
#if R_VERSION < R_Version(4, 5, 0)
// R versions older than 4.5.0 released use the old name of the function
#define isDataFrame(x) (isFrame(x))
#endif
// later:
if (!isVector(thiscol) || isDataFrame(thiscol))
// ^^^^^^^^^^^ introduced in R-4.5Status in data.table: change reverted in #6244, waiting for R-4.5.0 to release with the new interface.
OBJECT
Used in src/assign.c to test whether S3 dispatch is possible on an object before spending CPU time on constructing and evaluating an R-level call to as.character instead of coerceVector.
Use
isObject.
Problem:
if (OBJECT(source) && getAttrib(source, R_ClassSymbol)!=R_NilValue) {
// ^^^^^^ non-API entry pointSolution:
if (isObject(source)) {
// ^^^^^^^^ API entry pointMost likely, the check for getAttrib(source, R_ClassSymbol) is superfluous, because when used correctly, R API maintains the object bit set only when the class attribute is non-empty.
Status in data.table: not fixed yet.
Conclusion
While data.table could get rid of most of its non-API use with relative ease, either using a different name for the function (STRING_PTR_RO, GetOption1) or adding a wrapper for R < 4.5 (ANY_ATTRIB, findVar), two interfaces will require a significant amount of work.
Replacing the use of TRUELENGTH and related functions will require implementing two features from scratch: a set of ALTREP classes for growable vectors (with the previous implementation hidden in #ifdef for R < 4.3) and pointer-keyed hash tables for string and column marking.
It is not currently clear how to replace the use of ATTRIB.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}